DICTIONNAIRE DES DONNEES
Historique du document
|
Auteur
|
Description MAJ | Date de MAJ |
|---|---|---|
| Olivier TONCK | Version initiale | 23/11/2021 |
| Olivier TONCK | Prise en compte des remarques du point du 26/11/2021 | 21/12/2021 |
| Olivier TONCK | Prise en compte des remarques du point du 03/01/2022, consistant principalement à l’ajout des tables de stockage des mesures “complémentaires” | 17/01/2022 |
| Olivier TONCK | Prise en compte des dernières évolutions pour version livrable | 05/05/2022 |
| Olivier TONCK | Ajout de la colonne count_point_models.percentile_value | 24/06/2022 |
| Olivier TONCK |
Ajout de la colonne measure_sources.no_realtime_delay |
13/07/2022 |
| Olivier TONCK | Passage de la colonne trained_model en nullable | 12/09/2022 |
| Olivier TONCK |
Ajout de la table default_flows Modification de la description du champ aggregated_value Ajout des agrégats continus pour les agrégations hebdomadaires, mensuelles et annuelles suite à la mise à jour vers TimescaleDB 2.10.1 Augmentation des longueurs max. des champs points.station_name, count_point_name et chanel_code pour intégration référentiels DIRCE et Métropole de Lyon |
15/05/2023 |
| Olivier TONCK |
Modifications de la table count_point_models relatives aux modifications du module IA :
|
30/05/2023 |
| Olivier TONCK | Ajout du champ lanes_channel_codes à la table count_point_modals (pour l’agrégation toutes voies des données DIRIF) | 28/09/2023 |
| Olivier TONCK | Ajout du champ last_date_quality_data à la table count_points | 20/03/2024 |
| Olivier TONCK | Ajout du lien vers le dictionnaire des données du Si trafic route (pour la partie brique des dépôts) | 05/07/2024 |
| Olivier TONCK | Activation de la compression timescaleDB pour les tables de mesures | 15/11/2024 |
| Olivier TONCK | Ajout du champ count_points.suppressed | 29/11/2024 |
| Olivier TONCK | Modification des vues représentant les données agrégées | 08/04/2025 |
| Olivier TONCK |
|
07/05/2025 |
| Mélanie CORTINA | Modification des vues représentant les données agrégées | 17/07/2025 |
| Olivier TONCK | Passage de la documentation au format markdown | 01/08/2025 |
| Olivier TONCK | Ajout de la colonne count_points.hide_traffic_states | 10/09/2025 |
| Mélanie CORTINA | Ajout des tables api_tracking_measures et operator_reports | 10/09/2025 |
TABLE DES MATIÈRES
Le présent document constitue le modèle physique des données et le dictionnaire des données du projet AVATAR (Analyse & Visualisation Automatique de données de TrAfic Routier).
Il a pour objectif de décrire précisément le modèle de données relationnel de la base de données mise en œuvre en vue de répondre au besoin décrit dans le modèle conceptuel des données.
Les principaux paragraphes de ce document sont les suivants :
Conventions et règles de nommage ;
Modèle physique des données .
Les règles de nommages retenues pour le modèle de données d’AVATAR sont :
L’utilisation de la langue anglaise pour les noms des tables et champs (à l’exception des champs directement issus des référentiels BD TOPO et BD PR, cf. La table “landmarks” et La table “roadlinks”),
L’utilisation du pluriel pour le nom des tables,
L’utilisation de lettres minuscules pour le nom des tables et champs (à l’exception des champs directement issus des référentiels BD TOPO et BD PR, cf. La table “landmarks” et La table “roadlinks”, dans lesquelles les noms des champs sont en majuscules),
L’utilisation du séparateur “_” entre les mots dans le nom des tables et champs (tout en considérant que les mots “landmark” et “roadlink” sont unitaires, d’où les noms de tables “landmarks” et “roadlinks” plutôt que “land_marks” et “road_links”),
L’utilisation du nom de champ “id” pour les clés primaires de chaque table,
L’utilisation de la règle de nommage “<nom_de_la_table_référencée_au_singulier>_id” pour le nom des clés étrangères (par exemple, le champ permettant de définir le gestionnaire associé à un point de comptage est par convention le champ “operator_id” de la table “count_points”).
La présence d’une clé primaire (champ “id”) est systématique pour chaque table, à l’exception :
Des tables d’association (La table count_point_roadlinks, La table “count_point_measure_sources”), dont la clé primaire est constituée de la paire des deux clés étrangères définissant la relation,
Des tables liées aux mesures (La table “raw_measures”, La table “fixed_measures”, Les vues “*_aggregated_measures”, pour lesquelles TimescaleDB impose la définition d’un clé primaire composée incluant l’horodate associée à la mesure.
Les géométries sont stockées non projetées (système EPSG:4326).
Par ailleurs, chaque table possède les champs “created_on” et “updated_on”, automatiquement renseignés par la base de données à l’aide de triggers, et correspondant à l’instant de création et de dernière modification de la ligne correspondante (à l’exception des tables “raw_measures”, “fixed_measures”, “extra_measures” et des vues “*_aggregated_measures” pour des raisons de performance et de frugalité en espace disque nécessaire pour ces tables constituées de très nombreuses lignes).
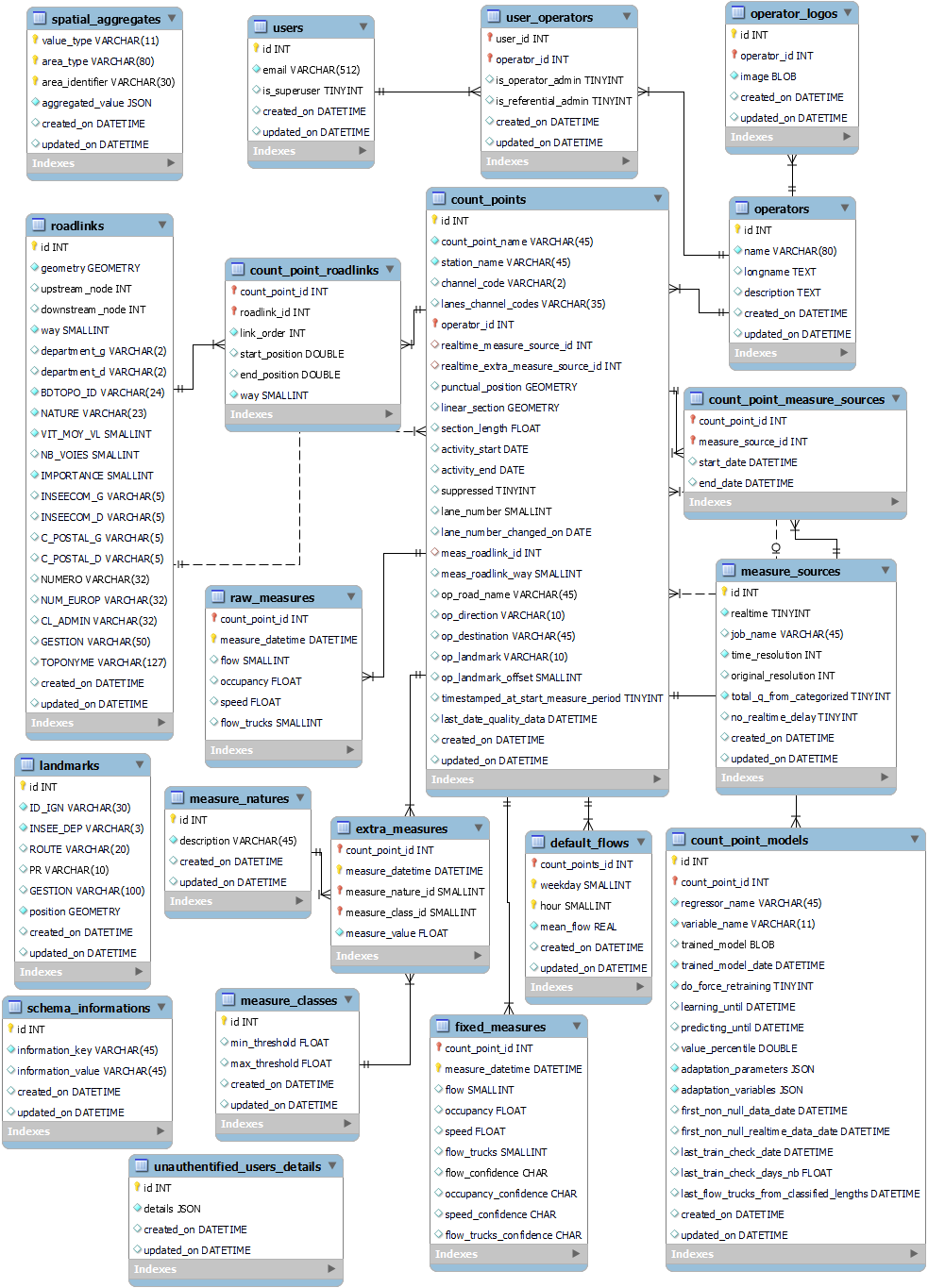
Le schéma suivant représente le Modèle Physique des Données d’AVATAR :
Modèle Physique des données d’AVATAR
L’ensemble des tables représentées ci-dessus font partie d’un schéma appelé “avatar” dans la base de données. Il existe également un schéma dédié au serveur WFS d’AVATAR (avatar_geoserver) décrit dans un paragraphe dédié (Le schéma “avatar_geoserver”).
Enfin, il existe également des schémas sitraficroute_* mis en place dans le cadre du futur SI trafic national (brique des dépôts intégrée à AVATAR, notamment), qu’on peut décrire ainsi :
Le diagramme suivant illustre cette organisation :
classDiagram
namespace sitraficroute_core {
class organizations
class users
}
namespace sitraficroute_deposite {
class deposite_users
class deposites
}
users <-- deposite_users
organizations <-- depositesLe logiciel utilisé pour réaliser le schéma “avatar” est MysSQL Workbench. Les codes graphiques utilisés sont les suivants :
Une clé jaune
( )
devant le nom d’un champ indique qu’il s’agit de la clé primaire de la
table,
)
devant le nom d’un champ indique qu’il s’agit de la clé primaire de la
table,
Une clé rouge
( )
devant le nom d’un champ indique qu’il s’agit d’une clé
étrangère,
)
devant le nom d’un champ indique qu’il s’agit d’une clé
étrangère,
Un losange plein
( )
devant le nom d’un champ indique qu’il est “NOT NULL” (ne pouvant pas
prendre la valeur NULL),
)
devant le nom d’un champ indique qu’il est “NOT NULL” (ne pouvant pas
prendre la valeur NULL),
Un losange vide
( )
devant le nom d’un champ indique qu’il n’est pas “NOT NULL” (il peut
prendre la valeur NULL)
)
devant le nom d’un champ indique qu’il n’est pas “NOT NULL” (il peut
prendre la valeur NULL)
Les cardinalités des relations sont représentées par :
Plusieurs lignes
(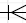 )
du côté d’une cardinalité “0..n”,
)
du côté d’une cardinalité “0..n”,
Une seule ligne
(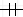 )
du côté d’une cardinalité “0..1”.
)
du côté d’une cardinalité “0..1”.
Par ailleurs, la table de correspondance entre les types indiqués sur le diagramme (types MySQL) et les types PostgreSQL, lorsque différents, est la suivante :
| Type MySQL | Type PostgreSQL “équivalent” |
|---|---|
| INT (pour les clés primaires auto-incrémentées) | SERIAL |
| DATETIME | TIMESTAMPTZ |
| TINYINT | BOOLEAN |
Les types PostgreSQL utilisés en pratique pour chaque champ sont indiqués dans le détail des tables donné aux paragraphes suivants.
La règle de lecture de la colonne “Spécificités” des tableaux présents dans les sous paragraphes suivants est la suivante :
La présence d’un “P” indique que la colonne fait partie de la clé primaire de la table,
La présence d’un “F” indique que la colonne est une clé étrangère (et référence donc la clé primaire d’une autre table),
La présence d’un “U” indique la présence d’une contrainte d’unicité sur la colonne correspondante. En cas de contrainte d’unicité sur plusieurs colonnes, il est indiqué “U1” pour l’ensemble des colonnes concernées par la première contrainte d’unicité composée de la table “U2” pour la seconde, etc…
La présence d’un “N” indique que le champ est défini comme étant non nullable (NOT NULL),
La présence d’un “I” indique la présence d’un index sur le champ correspondant. En cas d’index composé, il est indiqué “I1” pour l’ensemble des colonnes concernées par le premier index composé de la table, “I2” pour le second, etc…
La table “schema_informations” est une table permettant de stocker des métadonnées générales sur le modèle de données d’AVATAR, sous forme d’un ensemble de couples “clé + valeur”.
A ce jour, les clés suivantes sont définies :
| clé | |
|---|---|
| schema_version |
Version du schéma de la base de données AVATAR. Nécessaire pour pouvoir en gérer proprement les évolutions. Exemple : “1.0.0” |
| BD_TOPO_version |
Version de la BD TOPO actuellement représentée dans la base de données AVATAR. Permet de pouvoir identifier sans ambiguïté quelle version de la BD TOPO a été utilisée pour mettre à jour le contenu de la base de données et décider de la nécessité d’une éventuelle mise à jour. Exemple : “2021-09-15” |
| BD_PR_version |
Version de la BD PR actuellement représentée dans la base de données AVATAR. Permet de pouvoir identifier sans ambiguïté quelle version de la BD PR a été utilisée pour mettre à jour le contenu de la base de données et décider de la nécessité d’une éventuelle mise à jour. Exemple : “2018-07-31” |
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | SERIAL | 4 | PN | Clé primaire auto-incrémentée |
| information_key | VARCHAR | 45 | UN |
Nom de la clé (voir tableau ci-dessus pour les valeurs possibles). Exemple : “schema_version” |
| information_value | VARCHAR | 45 |
Valeur pour la clé information_key correspondante. Exemple : “1.0.0” |
|
| created_on | TIMESTAMPTZ | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | TIMESTAMPTZ | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
La table “landmarks” est la table permettant de stocker les points de repère de la version courante de la BD PR de l’IGN (version identifiée par la valeur associée à la clé “BD_PR_version” de la table “schema_information”).
Les champs dont les valeurs sont directement copiées de champs existants de la BD PR en conservent le nom et sont ainsi facilement identifiables (en langue française et en majuscules).
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | SERIAL | 4 | PN | Clé primaire auto-incrémentée |
| ID_IGN | VARCHAR | 30 | N |
Identifiant du point de repère dans la BD PR (identique au champ “ID_IGN” de la BD PR). Exemple : 01-3007 |
| INSEE_DEP | VARCHAR | 3 |
Code du département dans lequel se situe le PR (identique au champ “INSEE_DEP” de la BD PR). Exemple : 01 |
|
| ROUTE | VARCHAR | 20 |
Identifiant de la route associée au point de repère (identique au champ “ROUTE” de la BD PR). Exemple : D59 |
|
| PR | VARCHAR | 10 |
Etiquette associée au point de repère (identique au champ “PR” de la BD PR). Correspond souvent à un nombre de kilomètres, mais peut également prendre une valeur non numérique (pour identifier la fin d’une route par exemple). Exemples : “17”, “FRD”. |
|
| GESTION | VARCHAR | 100 |
Nom de l’organisme responsable du point de repère (identique au champ “GESTION” de la BD PR). Exemple : “CEREMA” |
|
| position | geometry(‘Point’, 4326) | NI | Position ponctuelle du point de repère. | |
| created_on | TIMESTAMPTZ | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | TIMESTAMPTZ | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
La table “roadlinks” est la table permettant de stocker les tronçons de route de la version courante de la BD TOPO de l’IGN (version identifiée par la valeur associée à la clé “BD_TOPO_version” de la table “schema_information”).
Les tronçons de route de la BD TOPO dont l’attribut “Sens” vaut “Sans objet” (sentiers, escaliers, pistes cyclables) ne sont pas représentés dans cette table.
Les champs dont les valeurs sont directement copiées de champs existants de la BD TOPO en conservent le nom et sont ainsi facilement identifiables (en langue française et en majuscules), à l’exception du champ “ID” renommé en “BDTOPO_ID” pour éviter toute ambiguïté avec la clé primaire de la table.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | SERIAL | 4 | PN | Clé primaire auto-incrémentée |
| geometry | geometry(‘Linestring’, 4326) | NI | Géométrie actuelle du tronçon de route | |
| upstream_node | INT | 4 | I | Identifiant du nœud amont au tronçon de route. Permet de définir la topologie du graphe routier. |
| downstream_node | INT | 4 | I | Identifiant du nœud aval au tronçon de route. Permet de définir la topologie du graphe routier. |
| way | SMALLINT | 2 | N |
Indicateur du sens de circulation possible sur le tronçon de route :
Ce champ est directement déduit du champ “Sens” de la BD TOPO mais converti d’une chaîne de caractère vers un entier pour limiter l’espace disque occupé et en faciliter l’exploitation. Rappel : les tronçons de route pour lesquels le champ “Sens” de la BD TOPO vaut “Sans objet” ne sont pas représentés dans la table “roadlinks”. |
| department_g | VARCHAR | 2 |
Département associé au tronçon de route (côté gauche). Permet de filtrer les capteurs par département, en fonction du tronçon de routes auxquels ils sont associés via la clé “meas_roadlink_id”. Exemple : “69” |
|
| department_d | VARCHAR | 2 |
Département associé au tronçon de route (côté droit). Permet de filtrer les capteurs par département, en fonction du tronçon de routes auxquels ils sont associés via la clé “meas_roadlink_id”. Exemple : “69” |
|
| BDTOPO_ID | VARCHAR | 24 | UN | Identifiant unique du tronçon de route dans la BD TOPO (champ “ID” de la BD TOPO). |
| NATURE | VARCHAR | 23 | N |
Nature du tronçon de route (champ NATURE de la BD TOPO). Exemple : “route à 1 chaussée”, “Type autoroutier”, … |
| VIT_MOY_VL | SMALLINT | 2 | N | Vitesse moyenne en kilomètres par heure des véhicules légers sur le tronçon de route, d’après la BD TOPO (champ identique). |
| NB_VOIES | SMALLINT | 2 | Nombre de voies de circulation du tronçon de route, d’après la BD TOPO (champ identique). Il s’agit du nombre de voies total pour les deux sens de circulation dans le cas des tronçons à double sens. | |
| IMPORTANCE | SMALLINT | 2 | NI | Importance du tronçon de route (de 1 à 6 du plus important au moins important) d’après la BD TOPO (champ identique). |
| INSEECOM_G | VARCHAR | 5 | Code INSEE de la commune associé au tronçon de route sur son côté gauche. | |
| INSEECOM_D | VARCHAR | 5 | Code INSEE de la commune associé au tronçon de route sur son côté droit. | |
| NUMERO | VARCHAR | 32 |
Numéro identifiant la route d’après la BD TOPO (champ identique). Exemple : “D306” |
|
| NUM_EUROP | VARCHAR | 32 |
Numéro d’axe européen identifiant la route d’après la BD TOPO (champ identique). Exemple : “E70/E15” |
|
| CL_ADMIN | VARCHAR | 32 |
Classe administrative du tronçon de route d’après la BD TOPO (champ identique). Exemples : “Autoroute”, “Départementale”, “Route intercommunale” |
|
| GESTION | VARCHAR | 50 |
Entité administrative rattachée au tronçon de route d’après la BD TOPO (champ identique). Exemples : “Ain”, “Savoie”, “Métropole de Lyon” |
|
| TOPONYME | VARCHAR | 127 |
Toponyme de la route associée d’après la BD TOPO (champ identique). Exemple : “Autoroute du soleil” |
|
| created_on | TIMESTAMPTZ | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | TIMESTAMPTZ | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
La table “operators” est la table permettant de stocker les gestionnaires des stations de comptage modélisées dans AVATAR.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | SERIAL | 4 | PN | Clé primaire auto-incrémentée |
| name | VARCHAR | 80 | UN |
Nom (unique) du gestionnaire. Exemples : “Nantes métropole”, “DIRO”, “CD44”. |
| longname | TEXT |
Nom long du gestionnaire Exemple : “Direction Interdépartementale des Routes Ouest” |
||
| description | TEXT | Description du gestionnaire | ||
| datasource_url | TEXT |
URL de la source de données (OpenData par exemple) Exemple : “https://opentransportdata.swiss/” |
||
| terms_of_use_url | TEXT | URL des Conditions Générales d’Utilisation de la donnée source | ||
| created_on | TIMESTAMPTZ | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | TIMESTAMPTZ | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
La table “operator_logos” est la table permettant de stocker les logos des gestionnaires des stations de comptage modélisées dans AVATAR.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | SERIAL | 4 | PN | Clé primaire auto-incrémentée |
| operator_id | INT | 4 | NF | Clé étrangère permettant d’identifier l’opérateur associé au logo. |
| image | BYTEA | N | Contenu binaire d | |
| created_on | TIMESTAMPTZ | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | TIMESTAMPTZ | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
La table “count_points” est la table permettant de stocker les points de comptage modélisés dans AVATAR.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | SERIAL | 4 | PN | Clé primaire auto-incrémentée |
| count_point_name | VARCHAR | 45 | U1U2U3N |
Identifiant (unique pour un gestionnaire donné) du point de comptage. Exemple DIRO : “MWL44.B1” Exemple Nantes Métropole : “6” Exemple CD44 : “MWL44.C1” |
| station_name | VARCHAR | 60 |
Nom de la station. Exemple DIRO : “N165 _EX-36 SAUTRON” Exemple Nantes Métropole : “Bellamy I5” Exemple CD44 : “MWL44.C” |
|
| channel_code | VARCHAR | 1 |
Caractère identifiant le canal associé au point de comptage. Exemple : “4” |
|
| lanes_channel_codes | VARCHAR | 35 | Liste des caractères identifiant les codes canal associés aux différentes voies de circulation du point de comptage. Permet de réaliser l’agrégation toutes voies au moment de l’acquisition des données correspondantes. | |
| operator_id | INT | 4 | FU1N | Clé étrangère permettant d’identifier le gestionnaire associé au point de comptage (cf. la table “operators”) |
| realtime_measure_source_id | INT | 4 | FU2 | Clé étrangère permettant d’identifier la source de mesure utilisée pour l’alimentation temps réel des mesures brutes du point de comptage |
| realtime_extra_measure_source_id | INT | 4 | FU3 | Clé étrangère permettant d’identifier la source de mesure utilisée pour l’alimentation temps réel des mesures additionnelles du point de comptage |
| punctual_position | geometry(‘Point’, 4326) | I | Position ponctuelle du point de comptage. | |
| linear_section | geometry(‘Linestring’, 4326) | I |
Géométrie linéaire associée au point de comptage, plaquée sur la géométrie des tronçons de route définis dans la table “roadlinks”. Utile à l’affichage du traficolor sans avoir à systématiquement recalculer cette géométrie à partir des informations de la table “count_point_roadlinks” |
|
| section_length | FLOAT | 4 | Longueur en mètres de la section linéaire associée au point de comptage. | |
| activity_start | DATE | 4 | Date de mise en service du point de comptage. Si définie, aucune mesure antérieure à cette date n’est attendue pour le point de comptage. | |
| activity_end | DATE | 4 | Date de fin de service du point de comptage. Si définie, aucune mesure postérieure à cette date n’est attendue pour le point de comptage. | |
| suppressed | BOOLEAN | 1 | Vrai si le point de comptage doit être masqué et accessible uniquement pour le gestionnaire (car il ne diffuse pas de la donnée correcte par exemple). | |
| hide_traffic_state | BOOLEAN | 1 | Vrai si les états de trafic du point de comptage ne doivent pas être présentés à l’utilisateur (capteur en amont d’un feu par exemple) | |
| lane_number | SMALLINT | 2 | Nombre de voies de circulation associées au point de comptage. Donnée facultative permettant d’améliorer l’interprétation des mesures de débit en particulier. | |
| lane_number_changed_on | DATE | 8 | Date à partir de laquelle la valeur du champ “lane_number” est réputée valide. | |
| meas_roadlink_id | INT | 4 | F | Clé étrangère permettant d’identifier le tronçon de route supportant le point de comptage et de remonter aux attributs correspondants (type de route, nature, nom de l’axe, etc…) |
| meas_roadlink_way | SMALLINT | 2 | Sens correspondant au point de comptage sur le tronçon de route identifié par la colonne “meas_roadlink_id” (1 dans le sens direct, -1 dans le sens indirect) | |
| op_road_name | VARCHAR | 45 |
Permet de préciser un nom d’axe routier pour le point de comptage dans le référentiel opérateur Exemple : “N144”. |
|
| op_direction | VARCHAR | 10 |
Permet de préciser le sens pour lequel sont faites les mesures du point de comptage tel qu’indiqué dans le référentiel opérateur. Exemple : “Sens 1” ou “Sens 2” |
|
| op_destination | VARCHAR | 45 |
Permet de préciser le champ “op_direction” de façon plus explicite en définissant une ville de destination par exemple. Exemple : “Vers Paris” |
|
| op_landmark | VARCHAR | 10 |
Nom du point de repère à partir duquel est identifié la position ponctuelle du point de comptage dans le référentiel opérateur, potentiellement différent du référentiel de la BD PR utilisée pour remplir la table “landmarks”, d’où l’absence de relation par clé étrangère à cette table. Exemple : “14PR75G” |
|
| op_landmark_offset | SMALLINT | 2 |
Offset en mètres par rapport au point de repère. Exemple : “300” |
|
| last_date_quality_data | TIMESTAMPTZ | 8 | Date de la dernière mesure brute reçue considérée valide par le module IA (indicateur A à D) | |
| last_date_flow_trucks_from_classified_lengths | TIMESTAMPTZ | 8 | Date de la dernière valeur de débit poids lourds calculée à partir des longueurs classifiées. | |
| created_on | TIMESTAMPTZ | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | TIMESTAMPTZ | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
La table “count_point_roadlinks” est une table d’association entre les tables “count_points” et “roadlinks”, permettant de définir l’emprise d’un point de comptage sur le réseau routier. Un point de comptage peut être associé à plusieurs tronçons de route.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| count_point_id | INT | 4 | PFU1 | Clé étrangère permettant d’identifier le point de comptage concerné |
| roadlink_id | INT | 4 | PF | Clé étrangère permettant d’identifier l’un des tronçons de route associés au point de comptage identifié par la colonne “count_point_id”. |
| link_order | INT | 4 | U1N | Indice (commençant à 0) du tronçon de route parmi l’ensemble des tronçons de route associés au point de comptage, dans le sens de l’écoulement du trafic. |
| start_position | DOUBLE | 8 |
Position en mètres du début de l’emprise du point de comptage sur le tronçon de route associé au point de comptage. Renseigné uniquement pour le premier tronçon de route associé au point de comptage (link_order vaut 0). Si la colonne “way” vaut -1 (cas d’un point de comptage est associé au sens inverse du tronçon), la valeur de “start_position” correspond à la distance entre la fin du tronçon (dans son sens direct) et la position considérée. |
|
| end_position | DOUBLE | 8 |
Position en mètres de la fin de l’emprise du point de comptage sur le tronçon de route associé au point de comptage. Renseigné uniquement pour le dernier tronçon de route associé au point de comptage (link_order de valeur maximale pour le point de comptage considéré). Si la colonne “way” vaut -1 (cas d’un point de comptage est associé au sens inverse du tronçon), la valeur de “end_position” correspond à la distance entre la fin du tronçon (dans son sens direct) et la position considérée. |
|
| way | SMALLINT | 2 | N | Vaut 1 si le point de comptage est associé au sens direct du tronçon routier identifié par “roadlink_id”, et -1 si le point de comptage est associé au sens indirect du tronçon routier identifié par “roadlink_id”. |
La table “measure_sources” est la table permettant de stocker des métadonnées sur les sources de données associées à un ou plusieurs points de comptage. Il s’agit d’identifier le job Talend responsable de l’acquisition des données brutes le cas échéant, la résolution temporelle des données, et les informations sur les éventuels pré-traitements apportés aux données brutes (réagrégation de données minute en données 6 minutes par exemple).
Une source de mesure peut être associée directement à un point de comptage s’il s’agit de la source de mesure active pour l’alimentation des données temps réel pour ce point de comptage (via la clé étrangère “realtime_measure_source_id” de la table “count_points”), ou indirectement pour conserver l’historique de l’ensemble des sources de mesures ayant servi à alimenter les données brutes d’un point de comptage au long du cycle de vie d’AVATAR via la table “count_point_measure_sources”.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | INT | 4 | PN | Clé primaire auto-incrémentée |
| realtime | BOOLEAN | 1 | N | Booléen indiquant si la source de la donnée est une source temps réel ou non. |
| job_name | VARCHAR | 45 | Nom du job Talend correspondant à la source de données le cas échéant | |
| time_resolution | INT | 4 | N |
Résolution temporelle des mesures brutes associées à la source de données, en secondes. Exemple : 360 pour une source de données 6 minutes |
| original_time_resolution | INT | 4 | Résolution temporelle du flux de données original, en secondes, dans le cas où le job talend d’acquisition des données procède à une réagrégation temporelle de données trop finement résolues pour l’utilisation d’AVATAR (Exemple des données Nantes métropole qui sont des données minutes, réagrégées en données 6 minutes par le job d’acquisition correspondant) | |
| total_q_from_categorized | BOOLEAN | 1 | N |
Vaut vrai si le flux total enregistré (colonne “flow” de la table raw_measures) a été calculé par le job talend correspondant en sommant les flux par catégories de longueur ou s’il est fourni directement pas le flux d’entrée. Exemple : vrai pour les données historiques DIRO ou CD44. |
| no_realtime_delay | BOOLEAN | 1 | Vaut vrai si la source de données temps réel permet l’acquisition de données en continu pour le jour courant (quasi temps-réel). Utile pour le calcul des tendances journalières et leur comparaison avec les données du jour. | |
| created_on | TIMESTAMPTZ | 8 |
Instant de création de la ligne dans la base de données (en UTC) En phase de validation de la plateforme, la clé “originalfilename” indique le chemin de la copie du fichier source de la donnée dans l’arborescence de sauvegarde correspondante. |
|
| updated_on | TIMESTAMPTZ | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
La table “count_point_measure_sources” est une table d’association entre les points de comptage et l’ensemble des sources de mesures associées aux données de mesure brutes acquises pour les points de comptage (y compris la source de mesure référencée par la colonne “realtime_measure_source_id” de la table “count_points”).
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| count_point_id | INT | 4 | PF | Clé étrangère permettant d’identifier le point de comptage concerné |
| measure_source_id | INT | 4 | PF | Clé étrangère permettant d’identifier la source de mesure concernée |
| start_date | TIMESTAMPTZ | 4 |
Horodate de début de la plage temporelle pour laquelle la source de mesures est responsable de l’alimentation des données brutes du point de comptage NULL pour la source de mesures de l’import historique initial pour le point de comptage. |
|
| end_date | TIMESTAMPTZ | 4 |
Horodate de fin de la plage temporelle pour laquelle la source de mesure est responsable de l’alimentation des données brutes du point de comptage NULL pour la source de mesures temps réel active pour le point de comptage. |
La table “raw_measures” est la table permettant de stocker mesures brutes effectuées par les différents canaux.
Il s’agit d’une hypertable TimescaleDB.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| count_point_id | INT | 4 | PNF |
Clé étrangère permettant d’identifier le point de comptage ayant produit la mesure (cf. la table “count_points”). Premier élément du couple (count_point_id, measure_datetime) constituant la clé primaire de la table “raw_measures”. |
| measure_datetime | TIMESTAMPTZ | 8 | PN |
Horodate du début de la période temporelle à laquelle correspond la mesure (en UTC). Second élément du couple (count_point_id, measure_datetime) constituant la clé primaire de la table “raw_measures”. |
| flow | SMALLINT | 2 | Débit horaire mesuré, tous types de véhicules, en véhicules / heure | |
| occupancy | FLOAT | 4 | Pourcentage d’occupation mesuré (compris entre 0 et 100 pour les valeurs valides). | |
| speed | FLOAT | 4 | Vitesse moyenne mesurée, en kilomètres par heure. | |
| flow_trucks | SMALLINT | 2 | Débit poids lourds horaire mesuré, en véhicules / heure |
La table “fixed_measures” est la table permettant de stocker les mesures corrigées et/ou complétées à partir des données brutes présentes dans la table “raw_measurements”.
Les colonnes définies dans cette table sont globalement identiques à celles de la table “raw_measurements”, auxquelles sont ajoutées des colonnes dédiées aux indices de confiance des grandeurs correspondantes.
Il s’agit d’une hypertable TimescaleDB.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| count_point_id | INT | 4 | PNF |
Clé étrangère permettant d’identifier le point de comptage ayant produit la mesure (cf. la table “count_points”). Premier élément du couple (count_point_id, measure_datetime) constituant la clé primaire de la table “raw_measures”. |
| measure_datetime | TIMESTAMPTZ | 45 | PN |
Horodate du début de la période temporelle à laquelle correspond la mesure (en UTC). Second élément du couple (count_point_id, measure_datetime) constituant la clé primaire de la table “raw_measures”. |
| flow | SMALLINT | 2 | Débit horaire, tous types de véhicules, en véhicules / heure | |
| occupancy | FLOAT | 4 | Pourcentage d’occupation (compris entre 0 et 100 pour les valeurs valides). | |
| speed | FLOAT | 4 | Vitesse moyenne, en kilomètres par heure. | |
| flow_trucks | SMALLINT | 2 | Débit poids lourds horaire mesuré, en véhicules / heure | |
| flow_confidence | “char” | 1 | Indicateur de confiance pour la valeur de la colonne “flow”. Se référer au document descriptif du module IA AVATAR pour l’interprétation de cette lettre. | |
| occupancy_confidence | “char” | 1 | Indicateur de confiance pour la valeur de la colonne “occupancy”. Se référer au document descriptif du module IA AVATAR pour l’interprétation de cette lettre. | |
| speed_confidence | “char” | 1 | Indicateur de confiance pour la valeur de la colonne “speed”. Se référer au document descriptif du module IA AVATAR pour l’interprétation de cette lettre. | |
| flow_trucks_confidence | “char” | 1 | Indicateur de confiance pour la valeur de la colonne “flow_trucks”. Se référer au document descriptif du module IA AVATAR pour l’interprétation de cette lettre. |
Les vues “hourly_aggregated_measures”, “daily_aggregated_measures”, “weekly_aggregated_measures”, “monthly_aggregated_measures” et “yearly_aggregated_measures” permettent la consultation des données de mesures corrigées / complétées (table “fixed_measures”) agrégées respectivement par heure, jour, semaine, mois et année.
A l’exception de la vue ” hourly_aggregated_measures”, pour laquelle la fonctionnalité pénalise les performances plus qu’elle ne les améliore, ces vues sont définies à l’aide de la fonctionnalité d’agrégats continus de TimescaleDB (https://docs.timescale.com/timescaledb/latest/how-to-guides/continuous-aggregates/) afin de permettre le calcul rapide des indicateurs agrégés quotidiens (cf. La table “spatial_aggregates”) et d’accélérer les requêtes de données agrégées temporellement depuis l’API et le tableau de bord.
Les colonnes de ces vues sont identiques à celles définies dans la table “fixed_measures”, où la colonne d’indicateurs de qualité a été remplacée par une colonne par variable de trafic présentant un tableau avec le nombre de mesures ayant obtenu chaque indicateur de qualité (tableau d’entiers à 9 éléments pour les 9 indicateurs de A à I pris dans cet ordre). Les agrégats sur des périodes supérieures à l’heure ne disposent que des données de débits journaliers (valeur de débit horaire moyennée sur la période multipliée par 24) (pas de vitesse ni taux d’occupation) et des comptes par indicateur de qualité.
La colonne “measure_datetime” est renommée en “aggregate_datetime” dans ces vues (exceptions pour les agrégations hebdomadaires : “aggregate_week” et mensuelles : “month_aggregate_datetime”).
Le code SQL définissant la vue “hourly_aggregated_measures” est le suivant :
CREATE VIEW hourly_aggregated_measures AS
SELECT count_point_id,
time_bucket(INTERVAL '1 hour', measure_datetime) AS aggregate_datetime,
round(AVG(flow))::integer as flow,
AVG(occupancy) as occupancy,
SUM(speed*flow)/SUM(NULLIF(flow, 0)) as speed,
round(AVG(flow_trucks))::integer as flow_trucks,
sum_confidence_c(flow_confidence) as flow_confidence_counts,
sum_confidence_c(speed_confidence) as speed_confidence_counts,
sum_confidence_c(occupancy_confidence) as occupancy_confidence_counts,
sum_confidence_c(flow_trucks_confidence) as flow_trucks_confidence_counts
FROM avatar.fixed_measures
GROUP BY count_point_id, aggregate_datetime;Les débits TV et PL horaires sont moyennés ainsi que les taux d’occupation. Les vitesses sont moyennées en pondérant par le débit associé. Pour des raisons de performance, les comptes par indicateur de qualité sont stockés sous forme de tableau et calculés par une fonction d’agrégation sur-mesure développée en C. Cette fonction est compilée dans le conteneur et importée dans postgresql via le code suivant :
CREATE OR REPLACE FUNCTION sum_confidence_c(confidence_array IN integer [9], confidence IN "char") RETURNS integer [9]
AS '$libdir/sum_confidence', 'sum_confidence_c'
LANGUAGE C STRICT;
CREATE OR REPLACE AGGREGATE sum_confidence_c ("char")
(
sfunc = sum_confidence_c,
stype = integer[9],
initcond = '{0,0,0,0,0,0,0,0,0}'
);Les agrégations journalières et supérieures exploitent la fonctionnalité d’agrégats continus hiérarchiques de Timescaledb (les agrégations annuelles sont calculées à partir des agrégations mensuelles, elles-mêmes calculées à partir des agrégations journalières comme les agrégations hebdomadaires), et sont mises à jour périodiquement. A titre d’exemple, le code de définition des agrégations journalières est le suivant. Il intègre le calcul de la première et dernière date des données agrégées, le nombre de valeurs, le nombre de valeurs non modifiées par le module IA (afin de donner des indicateurs de confiance aux agrégations annuelles), et les comptes détaillés par indicateur de qualité.
CREATE MATERIALIZED VIEW daily_aggregated_measures WITH (timescaledb.continuous) AS
SELECT count_point_id,
time_bucket(INTERVAL '1 day', measure_datetime, timezone => 'Europe/Paris') AS aggregate_datetime,
round(AVG(flow)*24)::integer as flow,
round(AVG(flow_trucks)*24)::integer as flow_trucks,
min(CASE WHEN flow IS NOT NULL THEN measure_datetime ELSE NULL END) as min_datetime,
max(CASE WHEN flow IS NOT NULL THEN measure_datetime ELSE NULL END) as max_datetime,
min(CASE WHEN flow_trucks IS NOT NULL THEN measure_datetime ELSE NULL END) as min_trucks_datetime,
max(CASE WHEN flow_trucks IS NOT NULL THEN measure_datetime ELSE NULL END) as max_trucks_datetime,
count(CASE WHEN flow_confidence IN ('A','B','C','D') THEN 1 END) as confident_values_nb,
count(flow) as all_values_nb,
sum_confidence_c(flow_confidence) as flow_confidence_counts,
sum_confidence_c(flow_trucks_confidence) as flow_trucks_confidence_counts
FROM avatar.fixed_measures
GROUP BY count_point_id, aggregate_datetime
WITH NO DATA; -- WITH NO DATA required since we're in a transaction. The following update policy will take care of refreshing it
ALTER MATERIALIZED VIEW daily_aggregated_measures set
(timescaledb.materialized_only = false);
SELECT add_continuous_aggregate_policy('daily_aggregated_measures',
start_offset => INTERVAL '10 year', -- had to add something there to
avoid an error with start time must be after the CA origin
end_offset => INTERVAL '1 day',
schedule_interval => INTERVAL '1 day');Les agrégations hebdomadaires reposent sur les agrégations journalières. Pour le calcul des comptes par indicateur de qualité, elles utilisent également une fonction C sur-mesure sommant les tableaux d’entiers élément à élément. Cette fonction est importée dans PostgreSQL via le code suivant :
CREATE OR REPLACE FUNCTION array_sum_c(confidence_array IN integer
[9], confidence_array_ IN integer [9]) RETURNS integer [9]
AS '$libdir/sum_confidence', 'array_sum_c'
LANGUAGE C STRICT;
CREATE OR REPLACE AGGREGATE array_sum_c (int [9])
(
sfunc = array_sum_c,
stype = integer[9],
initcond = '{0,0,0,0,0,0,0,0,0}'
);Les agrégations mensuelles ne fournissent une valeur que si le mois est complet (après reconstitution par le module IA). De plus, elles fournissent un débit pour les jours ouvrés uniquement en plus du débit moyen global.
Les agrégations annuelles ne fournissent une valeur que si au moins 10 valeurs mensuelles sont présentes (donc 10 mois complets), afin de se conformer aux règles Mélodie/Arpèges. Comme pour les agrégations mensuelles, sont calculés un TMJA et un TMJO, ainsi que les nombres de valeurs agrégées au total et nombres de valeurs agrégées non modifiées par le module IA, permettant de fournir un indice de confiance aux TMJA produits.
Les paramètres des politiques de mise à jour des agrégats continus sont les suivants :
| Agrégat continu | start_offset | end_offset | frequency |
|---|---|---|---|
| daily_aggregated_measures | 10 year | 1 day | 1 day |
| weekly_aggregated_measures | 10 year | 1 day | 1 week |
| monthly_aggregated_measures | 10 year | 1 day | 1 week |
| yearly_aggregated_measures | 10 year | 1 day | 1 week |
Un agrégat continu timescaleDB est également défini pour la gestion des indicateurs de qualité des données des points de comptages :
CREATE MATERIALIZED VIEW daily_quality WITH (timescaledb.continuous) AS
SELECT count_point_id,
time_bucket(INTERVAL '1 day', measure_datetime, 'Europe/Paris') AS aggregate_datetime,
flow_confidence,
count(count_point_id) as flow_confidence_count
FROM avatar.fixed_measures
GROUP BY count_point_id, aggregate_datetime, flow_confidence;
SELECT add_continuous_aggregate_policy('daily_quality',
start_offset => '10 year', -- had to add something there to avoid an error with start time must be after the CA origin
end_offset => INTERVAL '1 day',
schedule_interval => INTERVAL '1 day');Il permet de disposer de la proportion de chaque valeur d’indice de confiance des valeurs de débits par jour et par point de comptage, à utilité de l’espace dédié aux gestionnaires dans le dashboard AVATAR.
La table “extra_measures” est une table permettant de stocker des mesures supplémentaires par rapport à celles stockées dans la table raw_measures. Ces mesures supplémentaires ne sont pas prises en compte par le module de correction des données d’AVATAR, ni par les vues agrégées (cf. Les vues “*_aggregated_measures”).
Cette table permet de stocker tout type de mesure puisque chaque ligne référence une nature et une classe de mesure, définies dans les tables suivantes (cf. La table “measure_natures” et La table “measure_classes”).
Il s’agit d’une hypertable TimescaleDB.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| count_point_id | INT | 4 | PNF |
Clé étrangère permettant d’identifier le point de comptage ayant produit la mesure (cf. la table “count_points”). Premier élément du quadruplet (count_point_id, measure_datetime, measure_nature_id, measure_class_id) constituant la clé primaire de la table “extra_measures”. |
| measure_datetime | TIMESTAMPTZ | 8 | PN |
Horodate du début de la période temporelle à laquelle correspond la mesure (en UTC). Second élément du quadruplet (count_point_id, measure_datetime, measure_nature_id, measure_class_id) constituant la clé primaire de la table “extra_measures”. |
| measure_nature_id | SMALLINT | 2 | PNF |
Clé étrangère permettant d’identifier la nature de la mesure, cf. la table “measure_natures”. Troisième élément du quadruplet (count_point_id, measure_datetime, measure_nature_id, measure_class_id) constituant la clé primaire de la table “extra_measures”. |
| measure_class_id | SMALLINT | 2 | PNF |
Clé étrangère permettant d’identifier la classe de la mesure, cf. la table “measure_natures”. Quatrième élément du quadruplet (count_point_id, measure_datetime, measure_nature_id, measure_class_id) constituant la clé primaire de la table “extra_measures”. |
| measure_value | FLOAT | 4 | N | Valeur de la mesure |
La table “measure_natures” est une table permettant de stocker les natures des mesures stockées dans la table “extra_measures”, cf. La table “extra_measures”.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | INT | 4 | PN | Clé primaire auto incrémentée permettant d’identifier la nature de mesure. |
| description | VARCHAR | 45 | N |
Description de la nature de la mesure. Exemple : “classified flow” |
| created_on | TIMESTAMPTZ | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | TIMESTAMPTZ | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
La table “measure_classes” est une table permettant de stocker la définition des classes pour les mesures classifiées présentes dans la table “extra_measures”.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | INT | 4 | PN | Clé primaire auto incrémentée permettant d’identifier la nature de mesure. |
| min_threshold | FLOAT | 4 |
Borne numérique minimum de la classe. Exemple pour la classe de longueur de 6 à 7 mètres : 6 |
|
| max_threshold | FLOAT | 4 |
Borne numérique maximum de la classe. Exemple pour la classe de longueur de 6 à 7 mètres : 7 |
|
| created_on | TIMESTAMPTZ | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | TIMESTAMPTZ | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
La table “count_point_models” est une table permettant de stocker les modèles entraînés par le module IA d’avatar. On sauvegarde ainsi un modèle par point de comptage et par grandeur de mesure.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | INT | 4 | PN | Clé primaire auto incrémentée permettant d’identifier le modèle entraîné. |
| count_point_id | INT | 4 | NU1F | Clé étrangère permettant d’identifier le point de comptage associé |
| regressor_name | VARCHAR | 45 | NU1 |
Nom du modèle (au cas où plusieurs modèles soient utilisés un jour. Pour l’instant on n’utilise que le RandomForest). Exemple : “Random-Forest” |
| variable_name | VARCHAR | 11 | NU1 |
Nom de la grandeur mesurée correspondante. Exemple : “flow” pour le débit |
| trained_model | BYTEA |
Modèle entrainé exporté avec la librairie python joblib, cf. https://scikit-learn.org/stable/modules/model_persistence.html Remarque : peut être NULL si les données historiques étaient présentes lors de l’apprentissage mais étaient toutes NULL pour la variable correspondante. |
||
| trained_model_date | TIMESTAMPTZ | 8 | N | Horodate de l’apprentissage |
| do_force_retraining | BOOLEAN | 1 | N | Booléen indiquant que le modèle a été marqué pour un réapprentissage à la prochaine exécution du module IA quotidien |
| learning_until | TIMESTAMPTZ | 8 | Horodate de la dernière donnée historique utilisée pour l’apprentissage | |
| predicting_until | TIMESTAMPTZ | 8 | Horodate de fin de prédiction des données effectuée entre la fin des données historiques et le début des données temps réel | |
| percentile_value | 1DOUBLE | 8 | Valeur du 95ème percentile de la grandeur mesurée sur l’historique. Permet le filtrage de données aberrantes par le module IA. | |
| adaptation_parameters | JSON | N |
Contient les paramètres de la méthode d’adaptation des données associés à ce modèle :
|
|
| adaptation_variables | JSON | N |
Contient les variables d’état de la méthode d’adaptation, afin que le module IA puisse repartir des valeurs obtenues d’une itération sur l’autre pour les variables suivantes :
|
|
| first_non_null_data_date | TIMESTAMPTZ | 8 | Date de la première donnée brute non NULL associée. Le module IA ne complète pas les données avant cette date. | |
| first_non_null_realtime_data_date | TIMESTAMPTZ | 8 | Date de la première donnée brute temps réel non NULL associée. Le module IA ne complète pas les données temps réel d’une grandeur de mesure tant qu’on n’a pas reçu une première valeur non NULL, même si des données historiques sont présentes. | |
| last_train_check_date | TIMESTAMPTZ | 8 |
Date de l’estimation du nombre de jours de données valides disponibles pour l’entraînement du modèle. Permet avec le champ “last_train_check_days_nb” de ne pas réaliser à chaque exécution du modèle IA quotidien de couteuses requêtes de données tant que le modèle n’a pas pu être entraîné par manque de données. |
|
| last_train_check_days_nb | REAL | 4 |
Nombre de jours de données valides disponibles pour l’entraînement du modèle à la date “last_train_check_date”. Permet avec le champ “last_train_check_date” de ne pas réaliser à chaque exécution du modèle IA quotidien de couteuses requêtes de données tant que le modèle n’a pas pu être entraîné par manque de données. |
|
| created_on | TIMESTAMPTZ | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | TIMESTAMPTZ | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
La table “spatial_aggregates” est une table permettant de stocker des indicateurs précalculés par zone géographique ou par gestionnaire, à usage de la page d’accueil du dashboard AVATAR (TMJs et tendances journalières).
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| value_type | VARCHAR | 11 | PN |
Vaut “tmjs” pour les TMJs et “daily_trend” pour les tendances journalières. Est constitutif de la clé primaire composée de la table. |
| area_type | VARCHAR | 80 | PN |
Type d’agrégation parmi :
Est constitutif de la clé primaire composée de la table. |
| area_identifier | VARCHAR | 30 | NU1 |
Identifiant de l’opérateur, département, région, métropole ou pays correspondant. Est constitutif de la clé primaire composée de la table. |
| aggregated_value | JSON | N |
Valeur de l’indicateur agrégé sous forme d’objet JSON. Pour les TMJs : une valeur de comptage par jour. Pour les tendances journalières : pour chaque jour de la semaine et chaque heure, les valeurs des quantiles 0, 0.2, 0.4, 0.6, 0.8, 1 et 0.5, et la liste des identifiants des points de comptages étant intervenus dans le calcul |
|
| created_on | TIMESTAMPTZ | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | TIMESTAMPTZ | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
La table “default_flows” est une table permettant de stocker les débits moyens des points de comptage pour un jour de la semaine et une heure donnés. Ces valeurs permettent de compléter les données manquantes dans le cadre du calcul des tendances journalières représentées en page d’accueil du tableau de bord AVATAR.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| count_point_id | INT | 4 | PN | Clé étrangère permettant d’identifier le point de comptage concerné |
| weekday | SMALLINT | 2 | PN | Jour de la semaine (lundi = 0, dimanche = 6) |
| hour | VARCHAR | 2 | PN | Heure du début de la plage horaire considérée |
| mean_flow | REAL | 4 | N | Comptage horaire moyen pour le point de comptage, le jour de la semaine et la plage horaire considérés |
| created_on | TIMESTAMPTZ | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | TIMESTAMPTZ | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
La table “users” est une table permettant de définir les comptes utilisateurs AVATAR. Bien qu’AVATAR utilise le SSO Orion du CEREMA, il reste de sa responsabilité de définir les permissions applicatives des utilisateurs de la plateforme.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | SERIAL | 4 | PN | Clé primaire auto-incrémentée |
| VARCHAR | 512 | UN | Adresse électronique de l’utilisateur, permettant de faire le lien avec son compte Orion. | |
| is_superuser | BOOLEAN | 1 | Indique si l’utilisateur est un super administrateur de la plateforme AVATAR | |
| created_on | TIMESTAMPTZ | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | TIMESTAMPTZ | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
La table “user_operators” est la table permettant de définir les permissions des utilisateurs par association à un gestionnaire et à des droits sur le référentiel correspondant ou sur l’administration des utilisateurs associés au gestionnaire.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| user_id | INTEGER | 4 | FPN |
Clé étrangère permettant d’identifier l’utilisateur concerné. Est constitutif de la clé primaire de cette table |
| operator_id | INTEGER | 4 | FPN |
Clé étrangère permettant d’identifier l’opérateur sur lequel l’utilisateur a des droits. Est constitutif de la clé primaire de cette table |
| is_operator_admin | BOOLEAN | 1 | Indique si l’utilisateur a la permission d’administrer les utilisateurs associés au gestionnaire “operator_id” | |
| is_referential_admin | BOOLEAN | 1 | Indique si l’utilisateur a la permission de modifier le référentiel opérateur du gestionnaire “operator_id”. | |
| created_on | TIMESTAMPTZ | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | TIMESTAMPTZ | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
La table “unauthentified_users_details” est la table permettant de sauvegarder les réponses des utilisateurs non authentifiés au formulaire apparaissant dans le tableau de bord avant le téléchargement des données.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | INTEGER | 4 | PN | Clé primaire de la réponse au formulaire |
| details | JSON | N |
JSON contenant les réponses aux différents champs du formulaire. Les clés du JSON sont les suivantes :
Exemple : {“organization_type”: “Rien de tout cela”, “organization_name”: “Test”, “purpose”: “Rien de tout cela”, “joining”: 1, “user_email”: “test@test.fr”, “user_name”: “Test Test”} |
|
| created_on | TIMESTAMPTZ | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | TIMESTAMPTZ | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
La table “api_tracking_measures” permet d’enregistrer les appels faits aux ressource API suivantes : RawMeasureDownload, FixedMeasureDownload, AggregatedMeasureDownload, ExtraMeasureDownload, RawMeasureList, FixedMeasureList, AggregatedMeasureList, ExtraMeasureList. Notons que sur cette table, un pg_cron planifié tous les 9 du mois permet de supprimer d’anciennes lignes dans le cas où la taille des lignes de la table dépasse 10 GB.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | SERIAL | 4 | PN | Clé primaire de l’appel à l’API |
| request_from_dashboard | BOOLEAN | Booléen spécifiant si l’appel à l’API a été fait depuis le dashboard Avatar | ||
| ressource | api_ressource_enum | Enum parmi les noms des ressources suivies : ‘RawMeasureList’, ‘RawMeasureDownload’, ‘FixedMeasureList’, ‘FixedMeasureDownload’, ‘AggregatedMeasureList’, ‘AggregatedMeasureDownload’ | Ressource de l’API requêtée | |
| aggregation_period | aggregation_period_enum | Enum parmi les fréquences d’agrégation autorisées : ‘hour’, ‘day’, ‘week’, ‘month’, ‘year’ | Période d’agrégation des données requêtée | |
| start_datetime | TIMESTAMPZ | 8 | Début de la période de données requêtée | |
| end_datetime | TIMESTAMPZ | 8 | Fin de la période de données requêtée | |
| count_point_ids | text | Ids des points de comptage requêtés séparés par des virgules | ||
| nb_measures_per_count_point | JSONB | Nombre de mesures renvoyées pour chaque point de comptage requêté | ||
| created_on | TIMESTAMPTZ | 8 | Instant de création de la ligne dans la base de données (en UTC) |
La table “operator_reports” permet de stocker les rapports gestionnaires.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| name | VARCHAR | 100 | Nom du rapport | |
| operator_id | INTEGER | 4 | F | Id du gestionnaire au quel appartient le rapport |
| start_datetime | TIMESTAMPZ | 8 | Date de début de la période traitée par le rapport | |
| end_datetime | TIMESTAMPZ | 8 | Date de fin de la période traitée par le rapport | |
| frequency | report_generation_frequency_enum | Seul ‘month’ autorisé pour le moment | Fréquence de génération de ce rapport | |
| report_file | text | Fichier html du rapport | ||
| created_on | TIMESTAMPZ | 8 | Date à laquelle la rapport a été enregistré dans la base |
Cette table correspond à la couche WFS homonyme, permettant de représenter les points de comptage par leur géométrie ponctuelle. Ses attributs sont très proches de ceux de la table avatar.count_points :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | SERIAL | 4 | PN | Clé primaire. Correspond à la clé primaire de la table count_points du schéma avatar. |
| count_point_name | VARCHAR | 45 |
Identifiant (unique pour un gestionnaire donné) du point de comptage. Exemple DIRO : “MWL44.B1” Exemple Nantes Métropole : “6” Exemple CD44 : “MWL44.C1” |
|
| station_name | VARCHAR | 60 |
Nom de la station. Exemple DIRO : “N165 _EX-36 SAUTRON” Exemple Nantes Métropole : “Bellamy I5” Exemple CD44 : “MWL44.C” |
|
| operator_id | INT | 4 | Clé étrangère permettant d’identifier le gestionnaire associé au point de comptage (cf. la table “operators”) | |
| operator_name | VARCHAR | 80 |
Nom (unique) du gestionnaire. Exemples : “Nantes métropole”, “DIRO”, “CD44”. |
|
| geom | geometry(‘Point’, 4326) | Position ponctuelle du point de comptage. | ||
| section_length | FLOAT | 4 | Longueur en mètres de la section linéaire associée au point de comptage. | |
| activity_start | DATE | 4 | Date de mise en service du point de comptage. Si définie, aucune mesure antérieure à cette date n’est attendue pour le point de comptage. | |
| activity_end | DATE | 4 | Date de fin de service du point de comptage. Si définie, aucune mesure postérieure à cette date n’est attendue pour le point de comptage. | |
| lane_number | SMALLINT | 2 | Nombre de voies de circulation associées au point de comptage. Donnée facultative permettant d’améliorer l’interprétation des mesures de débit en particulier. | |
| lane_number_changed_on | DATE | 8 | Date à partir de laquelle la valeur du champ “lane_number” est réputée valide. | |
| op_road_name | VARCHAR | 45 |
Permet de préciser un nom d’axe routier pour le point de comptage dans le référentiel opérateur Exemple : “N144”. |
|
| op_direction | VARCHAR | 10 |
Permet de préciser le sens pour lequel sont faites les mesures du point de comptage tel qu’indiqué dans le référentiel opérateur. Exemple : “Sens 1” ou “Sens 2” |
|
| op_destination | VARCHAR | 45 |
Permet de préciser le champ “op_direction” de façon plus explicite en définissant une ville de destination par exemple. Exemple : “Vers Paris” |
|
| op_landmark | VARCHAR | 10 |
Nom du point de repère à partir duquel est identifié la position ponctuelle du point de comptage dans le référentiel opérateur, potentiellement différent du référentiel de la BD PR utilisée pour remplir la table “landmarks”, d’où l’absence de relation par clé étrangère à cette table. Exemple : “14PR75G” |
|
| op_landmark_offset | SMALLINT | 2 |
Offset en mètres par rapport au point de repère. Exemple : “300” |
|
| channel_code | VARCHAR | 1 |
Caractère identifiant le canal associé au point de comptage. Exemple : “4” |
|
| last_date_quality_data | TIMESTAMPTZ | 8 | Date de la dernière mesure brute reçue considérée valide par le module IA (indicateur A à D) | |
| tmja_20xx | INTEGER | 4 | Valeur de TMJA du point de comptage pour les 5 dernières années complètes. |
Cette table correspond à la couche WFS homonyme, permettant de représenter les points de comptage par leur géométrie linéaire. Ses attributs sont très proches de ceux de la table avatar.count_points :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | SERIAL | 4 | PN | Clé primaire. Correspond à la clé primaire de la table count_points du schéma avatar. |
| count_point_name | VARCHAR | 45 |
Identifiant (unique pour un gestionnaire donné) du point de comptage. Exemple DIRO : “MWL44.B1” Exemple Nantes Métropole : “6” Exemple CD44 : “MWL44.C1” |
|
| station_name | VARCHAR | 60 |
Nom de la station. Exemple DIRO : “N165 _EX-36 SAUTRON” Exemple Nantes Métropole : “Bellamy I5” Exemple CD44 : “MWL44.C” |
|
| operator_id | INT | 4 | Clé étrangère permettant d’identifier le gestionnaire associé au point de comptage (cf. la table “operators”) | |
| operator_name | VARCHAR | 80 |
Nom (unique) du gestionnaire. Exemples : “Nantes métropole”, “DIRO”, “CD44”. |
|
| geom | geometry(‘Linestring’, 4326) | Géométrie linéaire associée au point de comptage, plaquée sur la géométrie des tronçons de route définis dans la table “roadlinks”. | ||
| section_length | FLOAT | 4 | Longueur en mètres de la section linéaire associée au point de comptage. | |
| activity_start | DATE | 4 | Date de mise en service du point de comptage. Si définie, aucune mesure antérieure à cette date n’est attendue pour le point de comptage. | |
| activity_end | DATE | 4 | Date de fin de service du point de comptage. Si définie, aucune mesure postérieure à cette date n’est attendue pour le point de comptage. | |
| lane_number | SMALLINT | 2 | Nombre de voies de circulation associées au point de comptage. Donnée facultative permettant d’améliorer l’interprétation des mesures de débit en particulier. | |
| lane_number_changed_on | DATE | 8 | Date à partir de laquelle la valeur du champ “lane_number” est réputée valide. | |
| op_road_name | VARCHAR | 45 |
Permet de préciser un nom d’axe routier pour le point de comptage dans le référentiel opérateur Exemple : “N144”. |
|
| op_direction | VARCHAR | 10 |
Permet de préciser le sens pour lequel sont faites les mesures du point de comptage tel qu’indiqué dans le référentiel opérateur. Exemple : “Sens 1” ou “Sens 2” |
|
| op_destination | VARCHAR | 45 |
Permet de préciser le champ “op_direction” de façon plus explicite en définissant une ville de destination par exemple. Exemple : “Vers Paris” |
|
| op_landmark | VARCHAR | 10 |
Nom du point de repère à partir duquel est identifié la position ponctuelle du point de comptage dans le référentiel opérateur, potentiellement différent du référentiel de la BD PR utilisée pour remplir la table “landmarks”, d’où l’absence de relation par clé étrangère à cette table. Exemple : “14PR75G” |
|
| op_landmark_offset | SMALLINT | 2 |
Offset en mètres par rapport au point de repère. Exemple : “300” |
|
| channel_code | VARCHAR | 1 |
Caractère identifiant le canal associé au point de comptage. Exemple : “4” |
|
| last_date_quality_data | TIMESTAMPTZ | 8 | Date de la dernière mesure brute reçue considérée valide par le module IA (indicateur A à D) | |
| tmja_20xx | INTEGER | 4 | Valeur de TMJA du point de comptage pour les 5 dernières années complètes. |
Le schéma suivant représente le modèle physique des données du shéma “sitraficroute_core” :
erDiagram
users {
serial id
varchar(512) email
integer organization_id
boolean is_representative
varchar(255) name
varchar(255) position
varchar(255) service
timestamp created_on
timestamp updated_on
}
organizations {
serial id
varchar(128) name
varchar(10) acronym
varchar(255) ign_name
integer declared_by
timestamp created_on
timestamp updated_on
}
organizations ||--|{ users : "contient"
users ||--|{ organizations : "a déclaré"Le code utilisé pour créer ce schéma en base est disponible ici.
La table “organizations” est la table permettant de stocker les organismes impliqués dans le SI trafic route, par exemple les gestionnaires routiers.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | serial | 4 | PN | Clé primaire auto-incrémentée |
| name | varchar | 128 | UN | Nom (unique) de l’organisme. Exemple : “Conseil Départemental de Loire Atlantique” |
| acronym | varchar | 10 | Acronyme ou sigle de l’organisme. Exemple : “CD44” |
|
| ign_name | varchar | 255 | Eventuel identifiant donné au champ “GESTION” de la BD TOPO pour les
tronçons de route pour lesquels l’organisme gestionnaire y est
identifié. Exemple : “Loire Atlantique” |
|
| declared_by | integer | 4 | F | Clé étrangère permettant d’identifier l’utilisateur ayant déclaré l’organisme dans le table “users” décrite ci-après. |
| created_on | timestamp | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | timestamp | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
Remarque : il n’existe pour le moment pas de champ explicite indiquant le type de l’organisme (par exemple, s’agit-il d’un gestionnaire routier ou non ?). Ce type est déduit implicitement des relations existantes entre un organisme et les dépôts réalisés pour lui : on suppose qu’un organisme pour lequel a été réalisé un dépôt de données de trafic est un gestionnaire routier.
La table “users” est la table permettant de stocker les utilisateurs déclarés dans le SI trafic route (pour le moment, les utilisateurs ayant paramétré leur compte dans la brique de dépôt).
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | serial | 4 | PN | Clé primaire auto-incrémentée |
| varchar | 512 | UN | Adresse électronique de l’utilisateur. Exemple : “nom.prenom@cerema.fr” |
|
| organization_id | integer | 4 | F | Clé étrangère permettant d’identifier l’organisme de l’utilisateur. Peut ne pas être renseigné si un utilisateur déclaré dans le SI trafic n’a pas encore renseigné son organisme d’appartenance. |
| is_representative | boolean | 1 | Vrai si l’utilisateur à coché qu’il réalise le dépôt pour le compte de gestionnaires tiers dans la brique de dépôt | |
| name | varchar | 255 | Nom de l’utilisateur. Peut ne pas être renseigné si un utilisateur déclaré dans le SI trafic n’a pas encore paramétré son compte utilisateur. | |
| position | varchar | 255 | Position / poste de l’utilisateur au sein de son organisme d’appartenance. Optionnel. | |
| service | varchar | 255 | Service dans lequel l’utilisateur exerce son poste au sein de son organisme d’appartenance. Optionnel. | |
| created_on | timestamp | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | timestamp | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
Le schéma suivant représente le modèle physique des données du shéma “sitraficroute_deposite” :
erDiagram
deposites {
serial id
integer organization_id
varchar(50) name
varchar(1024) comment
timestamptz date
varchar(10) type
varchar(10) format
varchar(1024) file_path
bigint file_size
timestamp created_on
timestamp updated_on
}
deposite_users {
integer user_id
integer deposite_id
varchar(10) user_deposite_rel_type
timestamp created_on
timestamp updated_on
}
deposites ||--|{ deposite_users : "est accessible par"Le code utilisé pour créer ce schéma en base est disponible ici.
La table “deposites” est la table permettant de stocker les dépôts réalisés avec la brique de dépôt du SI trafic route.
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| id | serial | 4 | PN | Clé primaire auto-incrémentée |
| organization_id | integer | 4 | FN | Clé étrangère permettant d’identifier l’organisme pour lequel a été réalisé le dépôt dans la table “organizations”. |
| name | varchar | 50 | N | Nom donné au depôt par le déposant |
| comment | varchar | 1024 | Eventuel commentaire laissé par le déposant au moment du dépôt | |
| date | timestamptz | 8 | N | Date du dépot (en UTC) |
| type | varchar | 10 | N | Type du dépôt, parmi ‘tmja’ et ‘vla’ |
| format | varchar | 10 | N | Format du dépôt, parmi ‘shp’, ‘csv’ et ‘hit’ |
| file_path | varchar | 1024 | NU | Chemin du fichier déposé relatif à la racine de l’arborescence des fichiers déposés. Se référer aux spécifications du module de dépôt pour le mode de construction de ce chemin. |
| file_size | bigint | 8 | N | Taille du fichier déposé, en octets. |
| created_on | timestamp | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | timestamp | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
La table “deposite_users” est la table permettant de définir les relations entre les dépôts et les utilisateurs (quel est l’utilisateur déposant, et quels sont les utilisateurs avec lesquels le dépôt a été partagé le cas échéant).
Le détail des colonnes de cette table est donné dans le tableau suivant :
| Champ | Type | Taille | Spécificités | Commentaire |
|---|---|---|---|---|
| user_id | integer | 4 | PFN | Clé étrangère permettant d’identifier l’utilisateur concerné par la relation dépôt - utilisateur dans la table “users”. |
| deposite_id | integer | 4 | PFN | Clé étrangère permettant d’identifier le dépôt concerné par la relation dépôt - utilisateur dans la table “users”. |
| user_deposite_rel_type | varchar | 10 | N | Type de relation dépôt - utilisateur, parmi : |
| created_on | timestamp | 8 | Instant de création de la ligne dans la base de données (en UTC) | |
| updated_on | timestamp | 8 | Instant de dernière modification de la ligne dans la base de données (en UTC) |
La compression des données proposée par timescaleDB (https://docs.timescale.com/api/latest/compression/) est mise en place pour les tables de données :
Une politique de compression des données datant de plus d’un mois a été mise en place pour l’ensemble de ces trois tables.
Le code correspondant est le suivant :
ALTER TABLE avatar.extra_measures SET (
timescaledb.compress,
timescaledb.compress_segmentby = 'count_point_id, measure_class_id, measure_nature_id'
);
SELECT add_compression_policy('avatar.extra_measures', INTERVAL '1 month');
ALTER TABLE avatar.raw_measures SET (
timescaledb.compress,
timescaledb.compress_segmentby = 'count_point_id'
);
SELECT add_compression_policy('avatar.raw_measures', INTERVAL '1 month');
ALTER TABLE avatar.fixed_measures SET (
timescaledb.compress,
timescaledb.compress_segmentby = 'count_point_id'
);
SELECT add_compression_policy('avatar.fixed_measures', INTERVAL '1 month');A l’avenir, il faudra sans doute définir des politiques de nettoyage automatique des données trop anciennes (https://docs.timescale.com/api/latest/data-retention/add_retention_policy/). Aucune n’est définie pour le moment.